
First there was the sentient—albeit, fictional—compactor robot WALL-E, whose name would go on to inspire the AI image generator DALL-E. Well, there’s now a new AI in town: VALL-E, Microsoft’s AI-powered neural codec language model that is scarily good at synthesising human voices.
Revealed earlier this week by Microsoft researchers, VALL-E was built off a previous AI technology introduced by Meta called EnCodec. VALL-E works pretty differently to your regular text-to-speech tools though; while the text-to-speech tools out there today typically work by manipulating waveforms to create “speech”, VALL-E can generate actual audio codec codes from both text and acoustic prompts. Basically, you can let VALL-E first listen to a sample of a person talking (it only needs to be at least three seconds long), and it’ll then analyse the way their voice sounds and breaks it down into what the researchers are calling ‘acoustic tokens’.
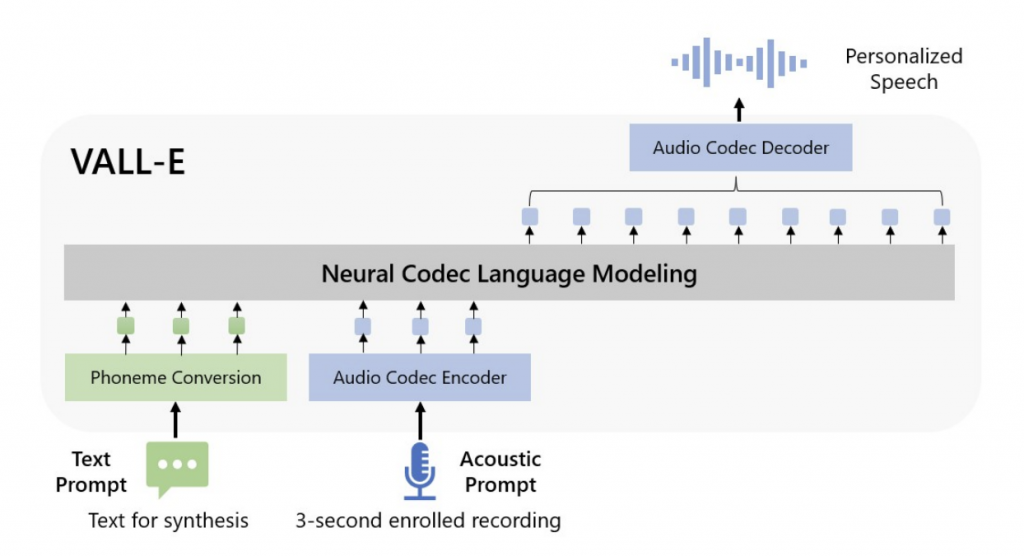
Using these acoustic tokens, you can give VALL-E a text prompt, in which VALL-E will then be able to generate an audio clip that both says the prompt while keeping the speaker’s vocal patterns, as well as closely imitate the acoustic environment of the sample audio and even generate variations of the sample voice by tweaking with the prompts used when generating the result.
You can check out some sample audio of VALL-E at work below:
Surprised there isn't more chatter around VALL-E
— Steven Tey (@steventey) January 9, 2023
This new model by @Microsoft can generate speech in any voice after only hearing a 3s sample of that voice 🤯
Demo → https://t.co/GgFO6kWKha pic.twitter.com/JY88vf4lYc
According to the researchers, VALL-E could one day be used for text-to-speech applications much better than the ones available out there today. It could also be used for audio content creation by pairing it with other AI tools such as the human chat AI model GPT-3. There’s potential for it to be used for speech editing too, using VALL-E to tweak recordings of a person’s speech or conversation. Thankfully though, Microsoft is seeming not opening it up to the public to mess about with for now, which is probably a good thing as people can easily abuse VALL-E for more harmful reasons.
The researchers also added that they’re looking at maybe building a detection model that can tell whether an audio clip is real or a VALL-E generation:
“Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker. To mitigate such risks, it is possible to build a detection model to discriminate whether an audio clip was synthesized by VALL-E. We will also put Microsoft AI Principles into practice when further developing the models,” – Microsoft VALL-E researchers
If you’re interested to know more about VALL-E, you can check out its demo page on Github. The researchers involved have not only provided more details about VALL-E there, but also a bunch of different VALL-E samples that you can play and listen to yourself.





{kind=link}